Writing
We will store one column given by row key and column name.Each thrift insert request blocks until data is stored in commit log and memtable - this is all, other operations (like replication) are asynchronous. Additionally client can provide consistency level, in this case call will be blocked until required replicas respond, but asides form this, write operation can be seen as simple append.
Commit log is required, because memtable exists only in memory, in case of system crash, Cassandra would recreate memtables from commit log.
Memtable can be seen as dedicated cache created individually for each column family. It's based on ConcurrentSkipListMap - so there is no blocking on read or insert.
Memtable contains all recent inserts, and each new insert for the same key and column will overwrite existing one. Multiple updates on single column will result in multiple entries in commit log, and single entry in memtable.
Memtable will be flushed to disk, when predefined criteria are met, like maximum size, timeout, or number of mutations. Flushing memtable creates SSTable and this one is immutable, it can be simply saved to disk as sequential write.
Compaction
Compaction process will merge few SSTables into one. The idea is, to clean up deleted data, and to merge together different modifications of single column. Before compaction, a few SSTables could contain value of single column, after compaction it will be only one.Reading
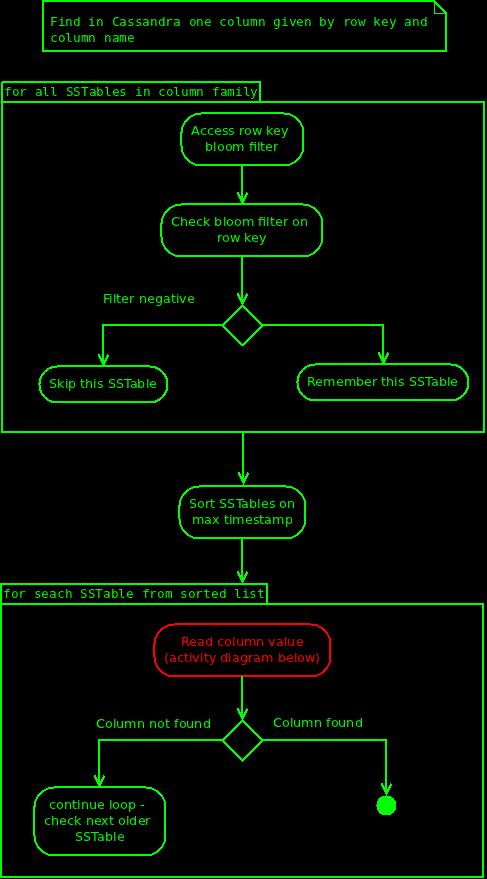
We will try to find value of single column within one row.First memtable is being searched, it's like write through cache, hit on it provides the most recent data - within single instance of course, not in a whole cluster.
As the second step Cassandra will search SSTables, but only those within single column family. SSTables are grouped by column family, this is also reflected on disk, where SSTables for each column family are stored together in dedicated folder.
Each SSTable contains row bloom filter, it is build on row keys, not on column names. This gives Cassandra the possibility to quickly verify, whenever given SSTable at least contains particular row. Row bloom filers are always hold in memory, so checking them is performant. False positives are also not problem anymore, because latest Cassandra versions have improved hashing and increased size of bit masks.
So ... Cassandra have scanned all possible SSTables within particular column family, and found those with positive bloom filter for row key. However the fact, that given SSTable contains given row, does not necessary mean, that is also contains given column. Cassandra needs to "look into SSTable" to check whenever it also contains given column. But it does not have to blindly scan all SSTables with postie bloom filter on row key. First it will sort them by last modification time (max time from metadata). Now it has to find first (youngest) SSTable which contains our column. It is still possible, that this particular column is also stored in other SSTables, but those are definitely older, and therefore not interesting. This optimization comes first with Cassandra 1.1 (CASSANDRA-2498), previous version would need to go over all SSTables.
Cassandra has found all SSTables with positive bloom filter on row key, and it has sorted them by last modification time, now it needs to find this one which finally has our column - it's time to look inside SSTable:
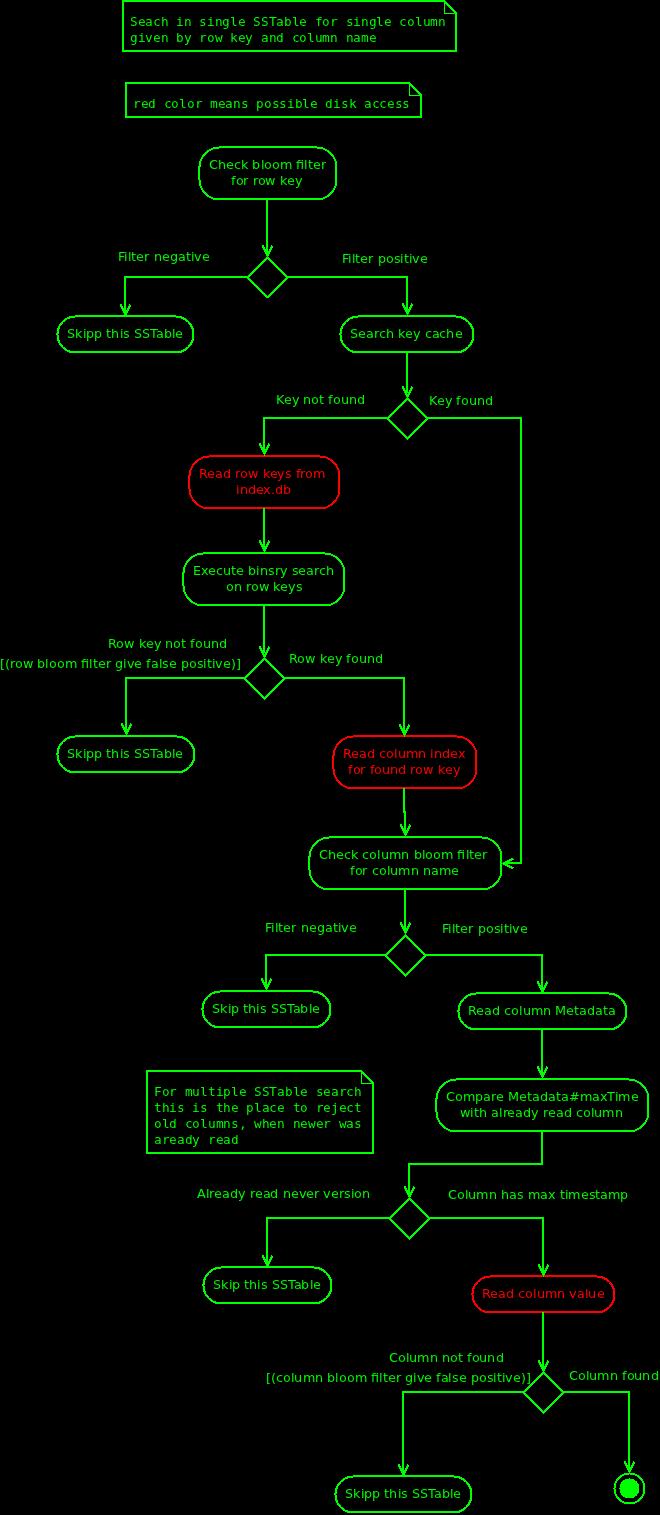
First Cassandra will read row keys from index.db, and find our row key using binary search. Found key contains offset to column index. This index has two informations: file offset for each column value, and bloom filter build on column names. Cassandra checks bloom filter on column name, if it is positive it tries to read column value - this is all.
For the record:
- index.db contains sorted row keys, not the column index as the name would suggest - this one can be found in data.db, under dedicated offset, which is stored together witch each row key.
- SSTable has one bloom filter build on row keys. Additionally each row hat its own bloom filter, this one is build on column names. SSTable containing 100 rows will have 101 bloom filters.
- In order to find given column in SSTable Cassandra will not immediately access column index, it will first check key cache - hit will lead directly from row key to column index. In this case only one disk access is required - to read column value.
Conclusion
Bloom filters for rows are always in memory, accessing them is fast. But accessing column index might require extra disk reads (row keys and column index), and this pro single SSTable. Reading can get really slow, if Cassandra needs to scan large amount of SSTables, and key cache is disabled, or not loaded yet.
Cassandra sorts all SSTables by modification time, which at least optimizes case where single column is stored in many locations. On the other hand, it might need to go over many SSTables to find "old" column. Key cache in such situation increases performance significantly.
Row keys for each SSTable are stored in separate file called index.db, during start Cassandra "goes over those files", in order to warm up. Cassandra uses memory mapped files, so there is hope, that when reading files during startup, then first access on those files will be served from memory.


{kind=link}